What is pseudonymization?
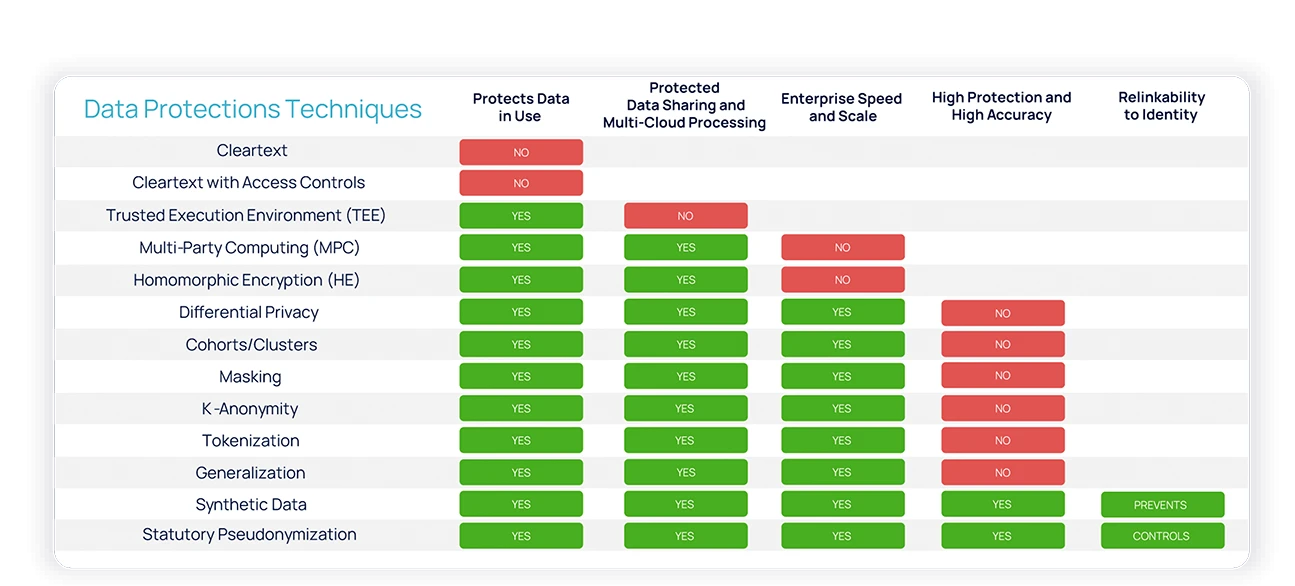
Pseudonymization is a data de-identification technique that replaces selected fields in a data record with artificial identifiers, or pseudonyms, to make the record less identifiable while still suitable for data processing and analysis. You can pseudonymize data in different ways. The traditional methods involve simple tokenization or masking, but they don’t satisfy the heightened GDPR requirements for pseudonymization. Statutory Pseudonymization, as defined by the GDPR,requires all five of these elements:
01
Protection of all data elements, including both direct and indirect identifiers.
02
Protection against singling-out attacks with either k-anonymity or aggregation.
03
Use of dynamism to ensure the use of different tokens at different times for different purposes and at different locations, so relinking is technologically prevented.
04
Inclusion of non-algorithmic lookup tables to account for the vulnerability of cryptographic techniques.
05
Controlled re-linkability to ensure source data is held separately by the data controller and available for relinking only for authorized purposes.
“Old” pseudonymization techniques enhance data privacy and security to an extent. But organizations relying on them don’t meet the regulatory requirements for processing data beyond a certain point, leaving them open to risks. In contrast,Statutory Pseudonymization not only makes organizations compliant with what is becoming the global de facto data protection standard, but it also gives them expanded processing rights because of the enhanced technical controls that flow with the data.